THe OpenJDK 21 beta 15 early access build (released 23 March 2023) adds an -Xlint warning to the Java compiler to notify Java developers when a class's constructor calls an overridable method. Specifically, changes for JDK-8015831 ("Add lint check for calling overridable methods from a constructor") and JDK-6557145 ("Warn about calling abstract methods in constructors") are avalable in OpenJDK 21 beta 15. CSR JDK-8299995 ("Add lint check for calling overridable methods from a constructor") provides background details and justificatiion for these new warnings.
Two example classes are needed to demonstrate the new warnings with a parent class whose constructor calls overridable methods implemented by the extending class.
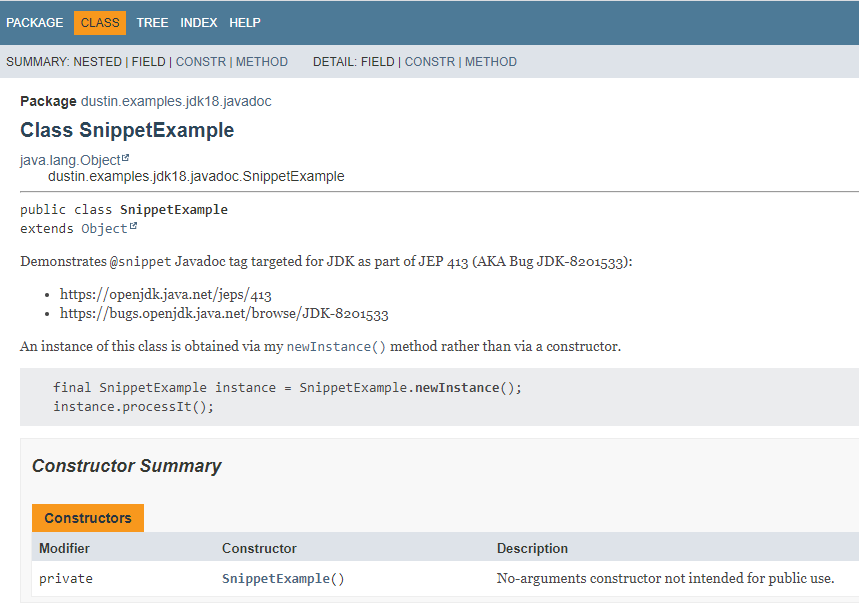
ParentWithAbstractMethod: Parent Class with abstract Method Called by Constructor
package dustin.examples.constructorcalls;
public abstract class ParentWithAbstractMethod
{
/**
* Constructor to be called by extending classes.
*/
protected ParentWithAbstractMethod()
{
initializeCustomLogic();
}
/**
* Initialize instance's custom logic.
*
* Because this {@code abstract} method is called by the constructor,
* it will trigger the "this-escape" {@code -Xlint} warning.
*/
protected abstract void initializeCustomLogic();
}
ConstructorCallsDemonstration: The Child/Extending Class
package dustin.examples.constructorcalls;
/**
* Demonstrate warnings introduced with JDK 21 Early Access Update b15.
*/
public class ConstructorCallsDemonstration extends ParentWithAbstractMethod
{
public ConstructorCallsDemonstration()
{
overridableInitializer();
privateInitializer();
finalInitializer();
initializeCustomLogic();
}
/**
* A child class CAN override this method called by constructor
* and will trigger "this-escape" {@code -Xlint} warning.
*/
protected void overridableInitializer()
{
}
/**
* A child class cannot override this method called by constructor
* and will NOT trigger "this-escape" {@code -Xlint} warning.
*/
private void privateInitializer()
{
}
/**
* A child class cannot override this method called by constructor
* and will NOT trigger "this-escape" {@code -Xlint} warning.
*/
protected final void finalInitializer()
{
}
@Override
protected void initializeCustomLogic()
{
}
}
When the above code is compiled with javac -Xlint, the new warnings are seen:

The command "javac -Xlint -sourcepath src -d classes src\dustin\examples\constructorcalls\*.java" generates this output:
src\dustin\examples\constructorcalls\ConstructorCallsDemonstration.java:10: warning: [this-escape] possible 'this' escape before subclass is fully initialized
overridableInitializer();
^
src\dustin\examples\constructorcalls\ParentWithAbstractMethod.java:10: warning: [this-escape] possible 'this' escape before subclass is fully initialized
initializeCustomLogic();
^
2 warnings
Executing the two code snippets shown above results in several observations:
- An
abstractmethod called from a constructor will lead to the new-Xlint this-escapewarning. - A concrete method that is overridable (not
privateorfinal) and called from a constructor will lead to the new-Xlint this-escapewarning. - A
finalmethod will not cause the-Xlint this-escapewarning to appear because sub-classes cannot override afinalmethod. - A
privatemethod will not cause the-Xlint this-escapewarning to appear because sub-classes cannot override (or even "see") aprivatemethod.
The associated CSR points out that just the new -Xlint this-escape warning can be enabled when running javac by specifying -Xlint:this-escape and this warning can be suppressed by applying the annotation @SuppressWarnings("this-escape") to the code for which the new warning should be suppressed.